PinnedPublished inTDS Archiverajini++: The Superstar Programming LanguageIntroducing rajini++, an esoteric programming language based on the dialogues of superstar Rajinikanth. The syntax and keywords used in…May 17, 202227May 17, 202227
Create your own programming in 10 minutes!Ever wanted to create your own esolang? With the rajiniPP project you can create one in less than 10 minutes!!!Jul 15, 2022Jul 15, 2022
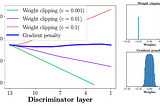
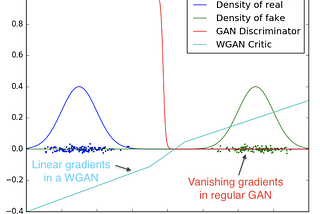
Published inTDS ArchiveDemystified: Wasserstein GAN with Gradient PenaltyWhy is Gradient Penalty better than gradient clipping? What is Gradient Penalty and how do we implement it?Oct 2, 2021Oct 2, 2021
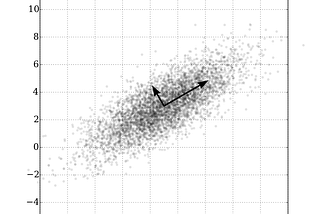
Published inTDS ArchivePrincipal Component Analysis Part 1: The Different Formulations.What is Principal Component Analysis? What are the Maximum Variance and Minimum Error formulations of PCA? How do we reduce dimensionality…Sep 29, 20212Sep 29, 20212
Published inTDS ArchiveReal-time Artwork Generation using Deep LearningAdaptive Instance Normalisation(AdaIN) for Style Transfer between any arbitrary content-style image pair.Sep 25, 20211Sep 25, 20211
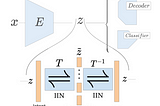
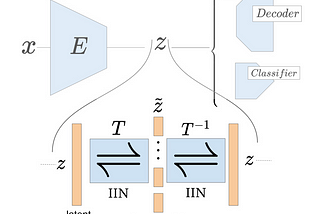
Published inTDS ArchiveLearning Disentangled Representations with Invertible(Flow-based) Interpretation NetworksWhat are disentangled representations?Sep 18, 20211Sep 18, 20211
Published inTDS ArchiveDemystified: Wasserstein GANs (WGAN)What is the Wasserstein distance? What is the intuition behind using Wasserstein distance to train GANs? How is it implemented?Sep 17, 2021Sep 17, 2021
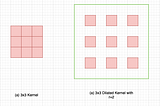
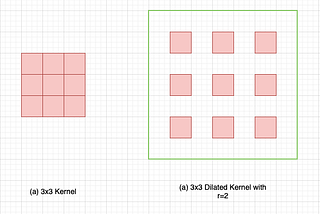
Published inTDS ArchiveA Primer on Atrous Convolutions and Depth-wise Separable ConvolutionsWhat are atrous/dilated and depth-wise separable convolutions? How are the different from standard convolutions? What are their uses?Sep 15, 20211Sep 15, 20211