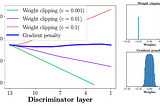
InTDS ArchivebyAadhithya SankarDemystified: Wasserstein GAN with Gradient PenaltyWhy is Gradient Penalty better than gradient clipping? What is Gradient Penalty and how do we implement it?Oct 2, 2021Oct 2, 2021
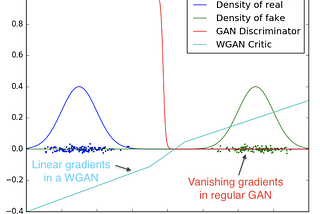
InTDS ArchivebyAadhithya SankarDemystified: Wasserstein GANs (WGAN)What is the Wasserstein distance? What is the intuition behind using Wasserstein distance to train GANs? How is it implemented?Sep 17, 2021Sep 17, 2021